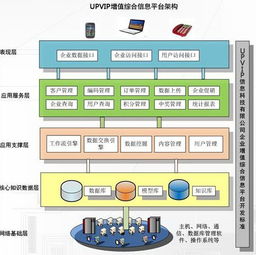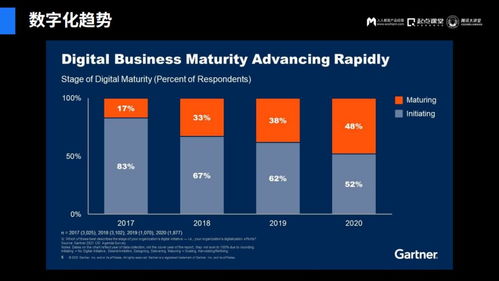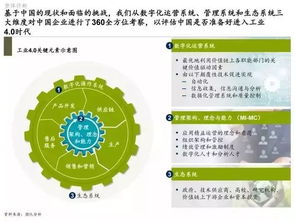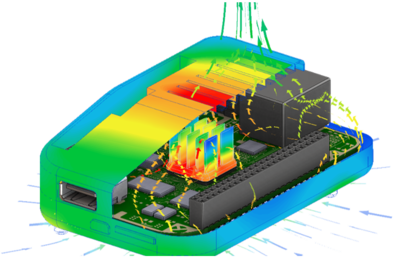
在當(dāng)今數(shù)字化浪潮席卷全球的背景下,高科技電子行業(yè)作為技術(shù)創(chuàng)新的前沿陣地,正以前所未有的速度產(chǎn)生海量、多源且復(fù)雜的工業(yè)數(shù)據(jù)。從半導(dǎo)體芯片的納米級制造,到智能終端的個性化用戶體驗,再到萬物互聯(lián)的龐大網(wǎng)絡(luò),每一環(huán)節(jié)都離不開高效、精準(zhǔn)的數(shù)據(jù)處理服務(wù)作為核心支撐。數(shù)據(jù)處理已不僅是輔助工具,而是驅(qū)動產(chǎn)業(yè)升級、優(yōu)化生產(chǎn)流程、激發(fā)產(chǎn)品創(chuàng)新的關(guān)鍵引擎,正深刻重塑著高科技電子行業(yè)的競爭格局與未來圖景。
一、數(shù)據(jù)處理服務(wù)的核心價值與應(yīng)用場景
在高科技電子行業(yè)中,數(shù)據(jù)處理服務(wù)貫穿于研發(fā)設(shè)計、智能制造、供應(yīng)鏈管理、質(zhì)量控制、市場營銷及售后服務(wù)等全生命周期。其核心價值主要體現(xiàn)在:
- 賦能研發(fā)與設(shè)計:通過處理仿真模擬數(shù)據(jù)、材料性能數(shù)據(jù)和用戶反饋數(shù)據(jù),加速新產(chǎn)品研發(fā)周期,優(yōu)化電路設(shè)計、功耗管理和散熱方案,實現(xiàn)性能與成本的精準(zhǔn)平衡。
- 驅(qū)動智能制造:在高度自動化的生產(chǎn)線中,實時處理來自傳感器、機器視覺系統(tǒng)和物聯(lián)網(wǎng)設(shè)備的運行數(shù)據(jù),實現(xiàn)生產(chǎn)過程的實時監(jiān)控、預(yù)測性維護、工藝參數(shù)優(yōu)化與動態(tài)調(diào)度,顯著提升良品率與設(shè)備綜合效率。
- 優(yōu)化供應(yīng)鏈與物流:整合分析全球供應(yīng)商數(shù)據(jù)、庫存數(shù)據(jù)、物流軌跡與市場需求預(yù)測,構(gòu)建敏捷、韌性強的供應(yīng)鏈體系,實現(xiàn)庫存精準(zhǔn)管理和物流效率最大化。
- 保障卓越質(zhì)量:運用大數(shù)據(jù)分析、機器學(xué)習(xí)算法對生產(chǎn)全流程的質(zhì)量檢測數(shù)據(jù)(如缺陷圖像、電性能參數(shù))進行深度挖掘,實現(xiàn)質(zhì)量問題的根源追溯、早期預(yù)警和閉環(huán)改進。
- 深化客戶洞察與智能服務(wù):分析用戶使用行為數(shù)據(jù)、設(shè)備運行狀態(tài)數(shù)據(jù),為產(chǎn)品功能迭代、個性化推薦以及預(yù)測性維護服務(wù)提供數(shù)據(jù)驅(qū)動決策,提升客戶滿意度與品牌忠誠度。
二、關(guān)鍵技術(shù)支撐與解決方案
為應(yīng)對電子行業(yè)數(shù)據(jù)高吞吐、低延遲、強關(guān)聯(lián)和多樣性的挑戰(zhàn),先進的數(shù)據(jù)處理技術(shù)方案不可或缺:
- 邊緣計算與云計算協(xié)同:在靠近數(shù)據(jù)源頭的設(shè)備端(邊緣)進行實時、輕量級的數(shù)據(jù)預(yù)處理和即時決策,減輕云端壓力并保障關(guān)鍵任務(wù)的低延遲;將聚合的、需要深度分析的數(shù)據(jù)傳輸至云端,利用其強大的存儲與算力進行復(fù)雜模型訓(xùn)練和大規(guī)模分析。
- 人工智能與機器學(xué)習(xí):利用深度學(xué)習(xí)進行圖像識別(如芯片缺陷檢測)、自然語言處理(分析客戶反饋)、預(yù)測性算法(設(shè)備故障預(yù)測、需求預(yù)測)等,從數(shù)據(jù)中自動發(fā)現(xiàn)模式、提煉知識。
- 大數(shù)據(jù)平臺與數(shù)據(jù)湖倉一體:構(gòu)建統(tǒng)一的企業(yè)級數(shù)據(jù)平臺,整合來自ERP、MES、SCM、CRM及物聯(lián)網(wǎng)的異構(gòu)數(shù)據(jù),打破數(shù)據(jù)孤島,支持實時流處理與批量分析,為上層應(yīng)用提供一致、可信的數(shù)據(jù)服務(wù)。
- 數(shù)據(jù)安全與隱私計算:采用加密技術(shù)、訪問控制、數(shù)據(jù)脫敏以及聯(lián)邦學(xué)習(xí)等隱私計算技術(shù),在數(shù)據(jù)流通與利用的全過程中,嚴(yán)格保護核心工藝參數(shù)、設(shè)計圖紙、用戶隱私等敏感信息,確保符合全球日益嚴(yán)格的數(shù)據(jù)合規(guī)要求。
三、面臨的挑戰(zhàn)與未來趨勢
盡管前景廣闊,高科技電子行業(yè)的數(shù)據(jù)處理仍面臨數(shù)據(jù)質(zhì)量參差不齊、系統(tǒng)集成復(fù)雜度高、專業(yè)復(fù)合型人才短缺、數(shù)據(jù)安全與跨境合規(guī)風(fēng)險等挑戰(zhàn)。數(shù)據(jù)處理服務(wù)將呈現(xiàn)以下趨勢:
- 實時化與智能化深度融合:從離線分析向?qū)崟r智能決策演進,實現(xiàn)生產(chǎn)與運營的自主優(yōu)化閉環(huán)。
- 云原生與平臺化普及:基于微服務(wù)、容器化等云原生技術(shù)構(gòu)建敏捷、彈性的數(shù)據(jù)處理架構(gòu),并通過平臺化降低使用門檻。
- 數(shù)據(jù)要素價值化:企業(yè)愈發(fā)重視數(shù)據(jù)資產(chǎn)的管理與運營,探索數(shù)據(jù)產(chǎn)品化、數(shù)據(jù)交易等新模式,釋放數(shù)據(jù)作為生產(chǎn)要素的核心價值。
- 綠色可持續(xù)發(fā)展:優(yōu)化數(shù)據(jù)處理能耗,利用數(shù)據(jù)智能優(yōu)化能源使用效率,助力電子行業(yè)實現(xiàn)“雙碳”目標(biāo)。
數(shù)據(jù)處理服務(wù)已成為高科技電子行業(yè)不可或缺的數(shù)字基礎(chǔ)設(shè)施和核心競爭力源泉。它如同行業(yè)的“智慧大腦”,將原始數(shù)據(jù)轉(zhuǎn)化為可行動的洞察與決策,驅(qū)動著產(chǎn)品、工藝和商業(yè)模式的持續(xù)創(chuàng)新。隨著技術(shù)的不斷演進與應(yīng)用的深化,那些能夠有效駕馭數(shù)據(jù)力量的企業(yè),必將在激烈的全球競爭中搶占先機,引領(lǐng)產(chǎn)業(yè)邁向更加智能、高效與可持續(xù)的新紀(jì)元。